Claude Code "Ngu Đi" Giữa Chừng? Đây Là Lý Do Và Cách Khắc Phục
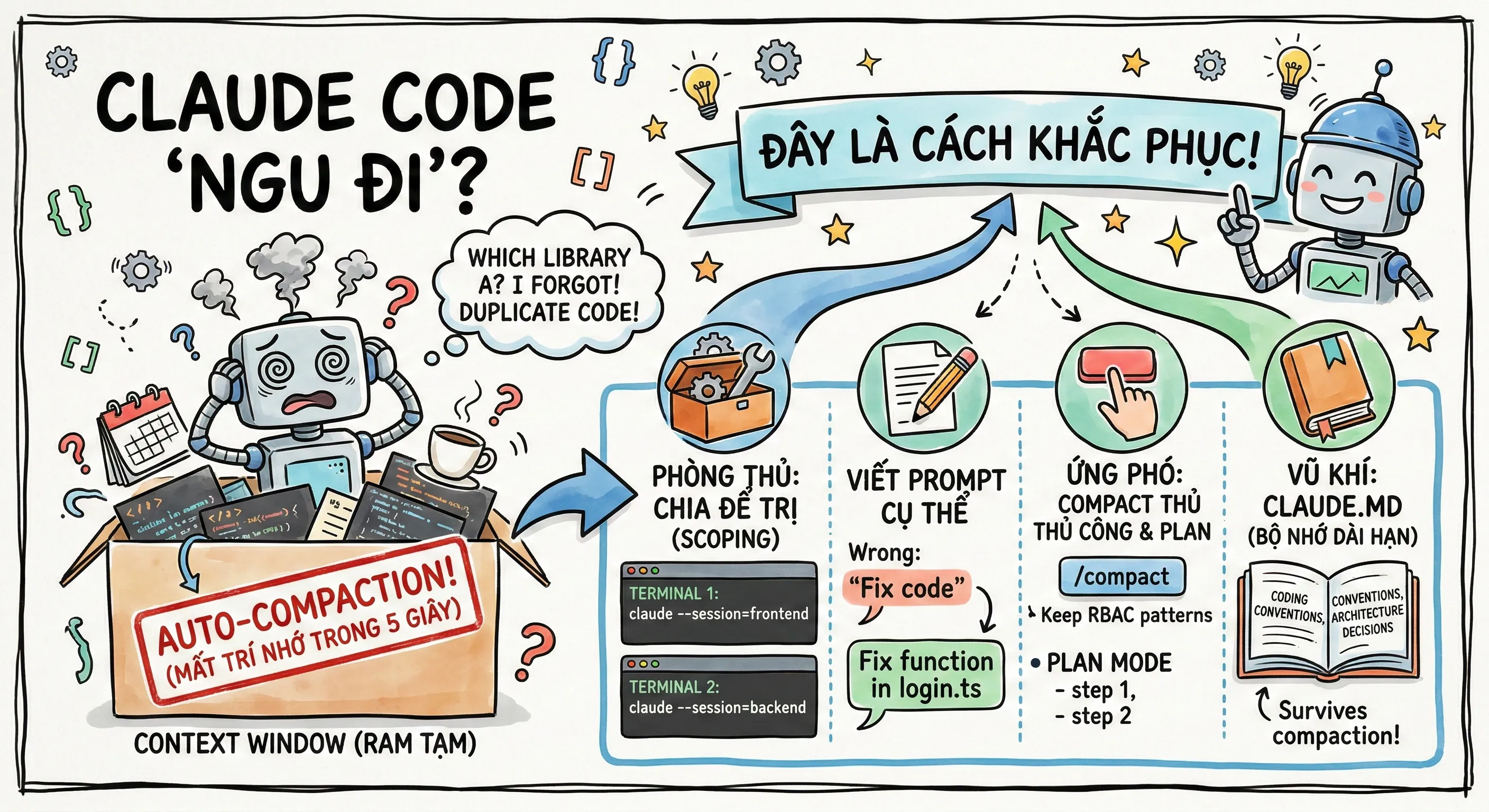
Có bao giờ bạn đang làm 1 tính năng lớn với Claude Code, mọi thứ đang chạy ngon lành, bùm — conversation bị Compact. Claude tự nhiên ngu đi, quên sạch trước đó mình nhắc tới vấn đề gì.
Bạn nói dùng library A, nó gợi ý library B. Bạn đã quyết kiến trúc theo hướng này, nó đề xuất hướng hoàn toàn khác. Code bắt đầu bị duplicate, pattern mâu thuẫn lung tung. Cảm giác như đang pair programming với người bị mất trí nhớ ngắn hạn vậy.
Mình từng bị như vậy suốt, tốn không biết bao nhiêu token vì phải giải thích lại từ đầu. Nên mình đi tìm hiểu sâu hơn xem chuyện gì đang xảy ra bên trong, và tìm được vài cách hạn chế khá hiệu quả. Bạn nào biết rồi thì hoan hỉ bỏ qua nhá, mình chia sẻ cho ai chưa biết thôi.
PHẦN 1: BẢN CHẤT VẤN ĐỀ — CONTEXT WINDOW VÀ COMPACTION
1.1 Context Window — "Bộ nhớ làm việc" của Claude
Trước hết phải hiểu cái này: context window là toàn bộ text mà Claude có thể tham chiếu khi tạo response. Bao gồm system prompt, conversation history, message hiện tại của bạn, response của Claude, và cả thinking tokens nếu bật extended thinking.
Quan trọng: đây KHÔNG PHẢI bộ nhớ dài hạn. Nó là "working memory" tạm thời cho mỗi session. Giống RAM của máy tính vậy — tắt máy là mất.
Giới hạn chính thức thì hầu hết model khoảng 200K tokens (tương đương ~150,000 từ, ~500 trang text). Claude Sonnet 4.5 trên Enterprise được 500K. Beta 1M context thì hỗ trợ trên Opus 4.6, Sonnet 4.6, Sonnet 4.5, Sonnet 4 nhưng chi phí 2x input khi vượt 200K.
Nhưng thực tế thì context window hiệu dụng nhỏ hơn nhiều so với con số chính thức. Lý do:
— System prompt, tools, MCP servers đều chiếm token sẵn rồi, chưa code gì đã mất một phần
— Extended thinking tokens cũng tính vào
— Hiện tượng "lost in the middle": Claude nhớ tốt phần đầu và cuối conversation, nhưng dễ bỏ sót thông tin nằm ở giữa
Tức là 200K tokens nghe hoành tráng, nhưng thực tế bạn có thể chỉ dùng hiệu quả được 60-70% thôi.
1.2 Compaction — Thủ phạm chính khiến Claude "mất trí nhớ"
Khi conversation tiến gần giới hạn context window (khoảng 75-80% capacity), Claude Code tự động kích hoạt cơ chế gọi là Compaction:
Bước 1: Phát hiện input tokens vượt ngưỡng trigger
Bước 2: Tóm tắt toàn bộ conversation thành summary ngắn gọn
Bước 3: Tạo compaction block chứa summary đó
Bước 4: Xóa bỏ tất cả message blocks trước compaction block
Bước 5: Tiếp tục conversation từ summary
Thấy vấn đề chưa? Compaction chỉ giữ lại khoảng 20-30% chi tiết gốc. Summary tập trung vào "what happened" (đã làm gì) nhưng mất đi "why" — các quyết định thiết kế, pattern đã thiết lập, và chi tiết kỹ thuật tinh tế.
Nói cách khác: Claude nhớ bạn đã refactor cái module auth, nhưng quên mất lý do bạn chọn approach đó, quên mất convention bạn đã thống nhất, quên mất edge case bạn đã cảnh báo.
1.3 Triệu chứng nhận biết — Làm sao biết Claude đã "mất trí nhớ"?
Nếu bạn thấy mấy dấu hiệu sau thì chắc chắn compaction đã xảy ra:
— Claude "quên" instruction đã đưa trước đó (bạn nói dùng Zustand, nó gợi ý Redux)
— Claude đề xuất approach hoàn toàn khác cho feature liên quan, vì đã quên quyết định kiến trúc trước đó
— Code bắt đầu bị duplicate hoặc contradictory patterns
— Claude đọc lại file đã xử lý trước đó, lãng phí token
— Mâu thuẫn với implementation choices đã thống nhất
Đây không phải lỗi của Claude. Đây là giới hạn cơ bản của cách LLM hoạt động. Hiểu rồi thì mình tìm cách bypass thôi.
PHẦN 2: CHIẾN THUẬT PHÒNG THỦ — LÀM SAO ĐỂ HẠN CHẾ BỊ "NGU ĐI"
2.1 Task Scoping — "Chia để trị"
Đây là anti-pattern phổ biến nhất mà mình thấy rất nhiều người mắc phải:
SAI: Nhồi mọi thứ vào 1 session
claude "Fix the frontend bug AND refactor the backend API AND update the tests"
ĐÚNG: Mỗi session một nhiệm vụ rõ ràng
Terminal 1: claude --session=frontend "Fix the UserCard component rendering in src/components/"
Terminal 2: claude --session=backend "Refactor the /api/users endpoint in src/routes/"
Mỗi session có context window riêng. 3 task nhỏ riêng biệt sẽ luôn hiệu quả hơn 1 session khổng lồ chứa cả 3. Đơn giản vậy thôi mà nhiều người (kể cả mình trước đây) cứ thích nhồi hết vào một chỗ cho "tiện".
2.2 Prompt Engineering — Viết prompt chuẩn để giảm token waste
Prompt mơ hồ = Claude phải scan rộng = tốn gấp 3x token cho cùng kết quả.
SAI — mơ hồ, Claude không biết focus vào đâu:
claude "improve this codebase"
claude "Read the entire project and understand it"
ĐÚNG — cụ thể, Claude chỉ đọc file cần thiết:
claude "add input validation to the login function in src/auth/login.ts"
claude "Read src/auth/login.ts and tests/auth.test.ts, then fix the failing test"
Khác biệt lớn lắm. Prompt cụ thể giúp Claude chỉ load những file thật sự cần, thay vì scan toàn bộ project rồi đốt hết context window.
2.3 Tắt MCP Servers không dùng
Cái này nhiều người hay quên. Mỗi MCP server được load vào context đều chiếm token. Nếu bạn cấu hình 5 MCP servers mà chỉ dùng 2, thì 3 cái còn lại đang ăn token free mỗi message. Tắt đi, để dành context cho thứ thật sự cần.
PHẦN 3: CHIẾN THUẬT ỨNG PHÓ — KHI COMPACTION ĐÃ XẢY RA
3.1 Manual Compact — Chủ động hơn Auto
Nguyên tắc: Compact thủ công tại logical breakpoints, đừng để auto-compact xảy ra random giữa task.
Auto-compact giống kiểu hệ thống tự ý dọn bàn làm việc của bạn khi thấy bừa quá — nó dọn sạch nhưng vứt luôn mấy tờ ghi chú quan trọng. Manual compact là bạn tự dọn, biết cái nào giữ cái nào bỏ.
/compact — compact cơ bản
/compact Focus on the API changes and preserve all file paths modified — compact nhưng giữ lại context cụ thể
/compact preserve the coding patterns we established and the RBAC decisions — compact nhưng preserve quyết định quan trọng
Bạn cũng có thể dùng Esc + Esc hoặc /rewind, chọn message checkpoint, chọn "Summarize from here" để chỉ compact từ 1 điểm nhất định thay vì toàn bộ.
3.2 Plan Mode + To-Do List — Persist qua Compaction
Đây là phát hiện khá hay từ cộng đồng: Plans và To-Do items có priority cao hơn trong compaction algorithm. Tức là khi Claude compact, nó sẽ ưu tiên giữ lại plans và to-do hơn là freeform conversation bình thường.
Ý nghĩa thực tế: trước khi bắt đầu task lớn, hãy yêu cầu Claude tạo plan trước. Liệt kê ra các bước cần làm dưới dạng to-do list. Khi compaction xảy ra, plan đó sẽ survive tốt hơn nhiều so với việc bạn chỉ chat qua chat lại bình thường.
Kiểu như viết meeting notes trước khi họp vậy — dù ai quên gì thì notes vẫn còn.
3.3 Subagents — Context Isolation, vũ khí mạnh nhất
Subagents là vũ khí mạnh nhất để quản lý context vì chúng chạy trong context window riêng biệt. Main agent không bị "ô nhiễm" bởi thông tin mà subagent xử lý.
Nhưng có một nguyên tắc vàng: Subagents là researchers, không phải implementers.
SAI — biến subagent thành "junior dev":
"frontend-dev agent, build the login page"
"backend-dev agent, build the API"
ĐÚNG — subagent nghiên cứu, main agent implement:
"Use subagents to investigate how our authentication system handles token refresh, and whether we have any existing OAuth utilities I should reuse."
Tại sao? Vì subagent chạy xong sẽ trả kết quả nghiên cứu về cho main agent dưới dạng summary gọn. Main agent có đủ context để implement mà không bị phình context window.
Nếu bạn để subagent tự implement thì kết quả có thể conflict với nhau vì các subagent không share context. Giống như thuê 3 thợ xây mà không cho họ nói chuyện với nhau vậy — mỗi người xây một kiểu.
(Nói thêm về topic multi-agent, mình có viết riêng 1 bài phân tích Agent Teams — tính năng cho phép nhiều Claude Code session chạy song song. Khác subagents ở chỗ teammates có thể nhắn tin trực tiếp cho nhau. Nhưng cơ chế bên trong cũng có vấn đề tương tự: mỗi teammate load lại toàn bộ context từ đầu, không có shared memory. Chi tiết mình đã phân tích kỹ trong bài đó, anh em quan tâm thì tìm đọc nhé.)
PHẦN 4: CLAUDE.md — "BỘ NHỚ DÀI HẠN" THỦ CÔNG
Đây là tip mà mình thấy ít người tận dụng tốt nhưng hiệu quả cực kỳ.
CLAUDE.md là file hướng dẫn project-level mà Claude đọc mỗi khi bắt đầu session. Nó survive mọi compaction vì nó được load lại từ đầu mỗi lần. Tức là bất cứ thứ gì bạn ghi trong CLAUDE.md, Claude sẽ LUÔN nhớ — bất kể conversation đã bị compact bao nhiêu lần.
Vấn đề là nhiều người viết CLAUDE.md không có cấu trúc, nhồi mọi thứ vào lung tung, kết quả là lãng phí ~3,000 tokens mỗi session mà hiệu quả chẳng bao nhiêu.
Gợi ý cấu trúc:
— Coding conventions: naming, patterns đang dùng
— Architecture decisions: những quyết định kiến trúc quan trọng và LÝ DO
— Stack: tech stack, libraries, versions
— Đừng viết chung chung kiểu "write clean code" — viết cụ thể kiểu "use Zustand for state management, NOT Redux. Use snake_case for API fields, camelCase for frontend."
Coi CLAUDE.md như onboarding doc cho nhân viên mới. Càng rõ ràng, nhân viên (Claude) càng ít hỏi lại và ít sai.
PHẦN 5: TOP 10 SAI LẦM PHỔ BIẾN
Xếp theo mức độ nghiêm trọng, từ kinh nghiệm cá nhân và tổng hợp từ cộng đồng:
[Critical]
Load toàn bộ project vào context → Saturate 80% context trước khi bắt đầu làm gì
Không dùng Plan Mode → Tốn 40% token nhiều hơn
Không compact thủ công → Context saturate sau 30 phút
Mất instructions sau compaction → Guidelines biến mất, Claude drift
[Warning]
5. Prompt mơ hồ → Tốn gấp 3x token cho cùng kết quả
6. 1 session cho mọi thứ → Giảm capacity hiệu dụng 3x
7. Không monitor context → 67% users không biết mình đang cạn context
8. Copy-paste khối lượng lớn → 500 dòng paste = 4,000 tokens lãng phí
9. Tiếp tục code trong session đã saturated → Quality giảm 45% sau 85% fill
[Minor]
10. CLAUDE.md không có cấu trúc → Lãng phí 3,000 tokens mỗi session
LỜI KẾT
Claude Code là tool cực mạnh, nhưng nó không phải magic. Hiểu cách context window và compaction hoạt động sẽ giúp bạn tránh được 80% frustration khi dùng.
Tóm lại 3 nguyên tắc lớn nhất:
— Chia nhỏ task, mỗi session một nhiệm vụ
— Compact thủ công tại logical breakpoints
— Viết CLAUDE.md chuẩn chỉnh như onboarding doc
Không cần fancy gì cả. Chỉ cần hiểu bản chất rồi áp dụng đúng là đã hiệu quả hơn hẳn rồi.
Anh em có kinh nghiệm gì hay thì chia sẻ thêm nhé, mình sẽ update bổ sung vào bài!