Second brain của bạn không chết vì thiếu data. Nó chết vì bạn không bao giờ mở nó ra.
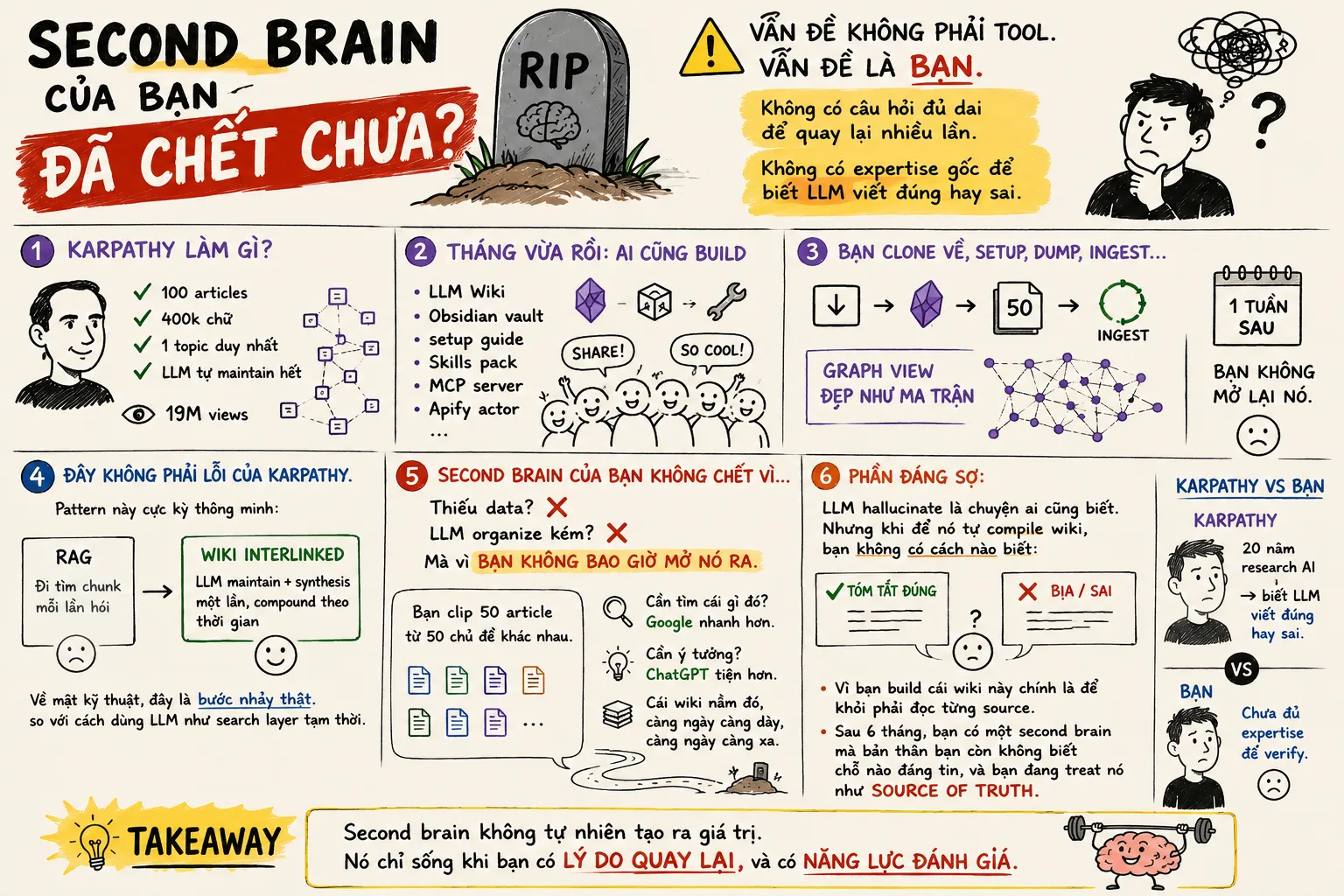
Cách đây hơn một tháng, Andrej Karpathy đăng một post trên X về cái second brain của ổng. 100 articles, 400k chữ, một topic duy nhất, LLM tự maintain hết. Ổng gọi nó là LLM Wiki. Post đó đạt 19 triệu views.
Tháng vừa rồi, cộng đồng phát cuồng.
Đâu cũng thấy guide setup. Obsidian vault structure. Skills pack cho Claude Code. MCP server. Apify actor. Tutorial 15 phút setup. Tutorial 1 giờ setup. Substack viết. Medium viết. Facebook tech group nào cũng có ít nhất một thread "anh em đã build chưa".
Mình cũng build. Đẹp thật. Setup xong trong một buổi sáng. Dump khoảng 30 article vào, để Claude Code chạy. Một tiếng sau, có wiki. Graph view nhìn như ma trận. Cross-reference đầy đủ. Mỗi page có summary, có backlink, có concept page riêng.
Mình save lại, đóng laptop, đi ăn trưa.
Hai tuần sau mình mới mở lại Obsidian. Không phải để query wiki. Mà vì mình cần tìm một cái note cũ từ trước khi build.
Đây không phải lỗi của Karpathy. Pattern ổng nghĩ ra cực kỳ thông minh. Thay vì RAG đi tìm chunk mỗi lần hỏi, LLM maintain một wiki interlinked, synthesis xảy ra một lần và compound theo thời gian. Về mặt kỹ thuật, đây là bước nhảy thật so với cách dùng LLM như search layer tạm thời. Một wiki cross-referenced rõ ràng dễ reasoning hơn nhiều so với một đống chunk rời rạc trong vector database.
Vấn đề không nằm ở pattern. Vấn đề nằm ở chỗ mọi người bỏ qua một câu hỏi cơ bản trước khi build.
Karpathy có thứ bạn không có
Đọc kỹ lại post gốc của Karpathy. Ổng nói rõ: 100 articles, 400k chữ, một topic duy nhất. Đó là research wiki cho một subject ổng đang đào sâu liên tục hàng tháng trời.
Ổng có lý do để quay lại wiki đó mỗi ngày. Vì ổng đang research deep. Câu hỏi mới phát sinh từ câu hỏi cũ. Concept mới phải xếp vào cạnh concept cũ. Mỗi lần mở wiki ra, ổng đều biết mình đang tìm gì, vì ổng đang giữa một cuộc điều tra dài.
Còn bạn build cái gì?
Bạn dump vào đó 50 article về 50 chủ đề khác nhau. Bài về AI agent. Bài về startup. Bài về design system. Bài về marketing. Bài về tâm lý học. Vì bạn nghĩ "biết đâu sau này cần".
Bạn không có cuộc điều tra nào. Bạn có một cái kho.
Khi cần tìm cái gì đó, bạn lên Google nhanh hơn. Lúc cần ý tưởng, hỏi ChatGPT tiện hơn. Lúc cần nhớ một concept, scroll lại Twitter còn tiện hơn. Cái wiki nằm đó, càng ngày càng dày, càng ngày càng xa.
LLM Wiki của Karpathy không chết vì thiếu data. Nó không chết với Karpathy vì ổng có một câu hỏi đủ dai để cần quay lại cùng một cơ sở tri thức nhiều lần.
Bạn không có câu hỏi đó.
Friction là kẻ giết người thầm lặng
Có một định luật nhỏ trong personal knowledge management mà ít ai nói thẳng. Một second brain chết khi friction để truy cập nó cao hơn friction để bypass nó.
Bạn save một article vào wiki. Một tuần sau bạn cần thông tin tương tự. Hai lựa chọn:
Lựa chọn A. Mở Obsidian, gõ query, đọc page wiki LLM viết, follow backlink nếu cần, có thể phải mở source gốc để verify.
Lựa chọn B. Cmd-T, gõ Google, đọc top result trong 3 giây.
Bạn chọn B. Lần nào cũng chọn B.
Không phải vì wiki tệ. Mà vì Google đã được tối ưu cho query 0-friction trong 25 năm. Bạn không cạnh tranh được với nó bằng cách build một interface chậm hơn.
Cái second brain bạn dựng lên chỉ tồn tại được nếu nó có thứ Google không có. Mà thứ Google không có chính xác là cái synthesis cá nhân của bạn về một domain bạn đang đào sâu, từ những source mà chỉ riêng bạn đã đọc và xử lý.
Nếu bạn dump article public vào wiki để LLM tóm tắt lại, bạn đang build một bản Google chậm hơn.
Cái wiki bạn không dám tin
Còn một vấn đề nữa, nặng hơn cả friction.
LLM hallucinate là chuyện ai cũng biết. Nhưng khi bạn để nó tự compile wiki từ raw source, có một động lực ngầm đáng lo: bạn build cái wiki này chính là để khỏi phải đọc từng source.
Đó là toàn bộ value proposition. Bạn không có thời gian đọc 50 article. Nên bạn để LLM đọc hộ, tóm tắt hộ, cross-reference hộ. Bạn chỉ đọc wiki page.
Vậy khi LLM bịa một câu trong page tóm tắt, ai phát hiện?
Không ai. Vì không ai đọc lại source.
Sau 6 tháng, bạn có một wiki dày, đẹp, organized. Trong đó có những claim mà bản thân bạn cũng không biết là LLM tóm tắt đúng từ source hay nó tự generate ra. Bạn đang treat cái wiki này như source of truth cá nhân. Bạn cite nó trong meeting. Bạn dựa vào nó để đưa ra quyết định.
Karpathy verify được vì ổng có 20 năm research AI. Khi LLM viết sai về một concept ML, ổng nhìn ra. Còn bạn dump một bài về macroeconomics vào, LLM viết hộ một page về monetary policy, bạn lấy gì để biết nó đúng?
Nguyên tắc đáng nhớ: bạn chỉ nên outsource cho LLM cái công việc mà bạn có thể spot-check được output. Còn outsource cả việc đọc và việc verify cùng một lúc cho cùng một con LLM, đó là bạn đang tự xây hệ thống niềm tin mà chính bạn không có quyền truy cập vào.
Khi nào LLM Wiki thực sự worth it
Mình không anti pattern này. Pattern Karpathy đề xuất giải quyết một bài toán thật. Nhưng nó worth it trong điều kiện cụ thể, không phải universal.
Bạn nên build nếu:
Bạn đang research một topic duy nhất trong nhiều tháng. Không phải nhiều topic. Một topic. Đủ deep để cần synthesis, đủ dài để compound effect có thời gian xảy ra.
Bạn có đủ expertise gốc trong domain đó để verify output. Khi LLM viết một câu sai, bạn nhìn ra trong 5 giây. Bạn không cần đọc lại source để biết.
Bạn có một query pattern lặp đi lặp lại. Không phải "lưu trữ phòng khi cần". Mà là "mỗi tuần mình quay lại hỏi 10 câu cùng về domain này".
Source của bạn không public hoặc không dễ Google. Meeting transcripts, internal docs, personal notes, conversation log. Những thứ Google không có. Nếu source của bạn là article public, bạn đang duplicate Google.
Nếu bạn không có cả 4 điều kiện trên, second brain bạn build ra sẽ là một đống markdown đẹp mà bạn không dùng và không dám tin.
Build trước cái nhỏ hơn
Thay vì lao vào setup vault Obsidian với 5 folder, schema CLAUDE.md, MCP server và Skills pack, bắt đầu nhỏ hơn nhiều.
Tuần này, chọn một câu hỏi duy nhất bạn đang muốn hiểu sâu. Không phải topic. Một câu hỏi. Ví dụ: "Event sourcing trong production thực sự trade-off chỗ nào?" hoặc "Cách design retention loop cho B2B SaaS dưới 100 customer ra sao?"
Đọc 5-10 source về nó trong tuần. Đọc thật, không nhờ LLM tóm tắt.
Sau mỗi source, mở một file markdown. Tự viết note. Một note. Vài đoạn ngắn. Ý chính. Chỗ bạn không đồng ý. Câu hỏi mới phát sinh.
Cuối tuần, mở 5 cái note ra, tự synthesis. Bằng não bạn, không phải LLM.
Sau một tháng, nếu bạn vẫn còn câu hỏi đó, vẫn còn quay lại, vẫn còn deposit và withdraw vào cái folder đó, lúc đó hãy nghĩ tới chuyện scale lên bằng LLM Wiki.
Còn nếu sau một tháng bạn mất hứng với câu hỏi, không quay lại nữa, thì cảm ơn trời bạn đã không setup 200 dòng schema và build Skills pack cho một cái second brain bạn không bao giờ mở.
Pattern này được bán với từ khóa "compound". Càng nhiều source, wiki càng giàu, càng giá trị theo thời gian. Nghe rất hay.
Nhưng compound chỉ xảy ra nếu bạn vừa liên tục thêm source mới, vừa liên tục quay lại query. Thiếu một trong hai, không có compound gì cả. Chỉ có một folder đầy file markdown.
Phần lớn người build LLM Wiki làm tốt vế đầu. Clip article, ingest, watch graph view dày lên. Cảm giác productive. Nhưng vế thứ hai, quay lại query, gần như không ai làm.
Bạn có sẵn sàng commit quay lại cái wiki đó mỗi ngày trong 6 tháng tới không? Trả lời được, build. Trả lời mơ hồ, đừng build.